中文标题:用于文本分析的ChatGPT?如何在会计研究中使用生成式LLMs
英文标题:ChatGPT for Textual Analysis? How to use Generative LLMs in Accounting Research
期刊:Management Science
发表时间:2025年
作者:de Kok, Ties
引用格式:de Kok, T. (2025). ChatGPT for textual analysis? How to use generative LLMs in accounting research. Management Science.
一、摘要
生成式大型语言模型(GLLMs),例如OpenAI的ChatGPT和GPT-4,正逐渐成为会计研究中文本分析任务的有力工具。GLLMs能够解决任何使用非生成式方法可解决的文本分析任务,以及先前只能通过人工编码解决的任务。尽管GLLMs新颖且强大,但它们也存在局限性,并带来了新的挑战,需要谨慎对待和尽职调查。本文重点介绍了GLLMs在会计研究中的应用,并将其与现有方法进行了比较。本文还通过解决模型选择、提示工程和确保构念效度等关键考量,提供了一个关于如何有效使用GLLMs的框架。在一个案例研究中,我通过检测盈余电话会议中的非答案(一项传统上难以自动化的任务)来展示GLLMs的能力。相对于现有的Gov等人(2021)的方法,新的GPT方法实现了96%的准确率,并将非答案错误率降低了70%。最后,我讨论了在使用GLLMs时解决偏见、可复现性和数据共享问题的重要性。总而言之,本文为研究人员、审稿人和编辑提供了有效使用和评估GLLMs进行学术研究的知识和工具。
二、研究背景
技术发展基础:自然语言处理与机器学习的快速进步催生了GLLMs,这类模型能以类似“智能自动补全”的方式生成文本,具备强大的语言理解与推理能力,如GPT系列模型可处理长达128,000个token(数百页文本)的输入,远超传统BERT模型的512个token限制。
会计研究需求:会计研究中存在大量文本分析场景(如ESG报告排放目标提取、业绩电话会议情绪分析、风险因素一致性对比等),传统方法存在明显短板——非生成式模型(如BERT)需大量训练数据且适配性差,人工编码则成本高、耗时长、规模受限,GLLMs的出现为解决这些痛点提供了可能。
GLLMs的概念及其工作原理:
概念:生成式大语言模型(generative large language models,GLLMs)是一类机器学习模型,它可以吸收和生成自然语言。其中最著名的例子是OpenAI的ChatGPT。“生成式”是GLLMs区别于以往模型的创新之处。
工作原理:GLLMs基于前面的标记(token)(一个词、词的部分、一个字符)来预测下一个标记。使用者提供提示符(prompt),模型依次预测补全每一个提示符。不同GPT模型的差异点在于其参数规模、调优和可用性。
GLLMS与其他LLMs的联系:
GPT和BERI是两种著名的LLMs模型。本研究探讨了它们之间的联系:
共同点:GPT和BERI模型都是强大的文本分析方法,利用了转换器体系结构及其迁移学习能力的优势。
差异点:BERT模型是更广泛的机器学习流程中的一个强大组成部分。GLLMs是独立运行的,使用者向其输入自然语言提示,模型生成完整内容,然后使用者通过解析该内容来获取结果。
优劣:GPT使用更为简便、灵活,因为通常所需训练数据较少,且更容易适配各种不同任务,然而其扩展成本高昂。BERT一旦成功完成训练,使用和扩展的速度会快得多,成本也低得多,但其需要昂贵的训练数据集。因此,GPT适用于中小规模的较复杂文本分析问题,而BERT适用于简单的大规模问题。
GLLMs与现有文本分析方法的比较:
优势:大型GPT模型往往无需额外训练,就能解决基本的客观性文本分析任务,免去了手动创建大量训练数据的时间和费用成本。相较于更为刻板的统计方法,自然语言提示在表达任务时更为灵活。具备的基本推理能力和对世界的理解,使得利用现有自然语言处理(NLP)技术难以或无法解决的任务变得可解。GLLMs能够处理更长的输入内容和文档。
劣势:相较于非生成式文本分析技术,GLLMs规模庞大,需要更多的处理资源,导致其成本更高且速度更慢。GLLMs存在出错的可能性,无法保证给出有意义的回复。因此,要实现较高的结构效度,需要研究人员谨慎行事并尽职尽责。大型GPT模型需要昂贵的硬件,且大多通过第三方供应商才能便捷使用。这导致在本地使用GLLMS可能无法实现,而将研究数据发送给外部方存在风险。
GLLMs与人工编码的比较:
生成式大语言模型(GLLMS)的强大功能和即开即用的特性,使其有望成为人工编码的替代方案。
优势:与人工编码相比,使用GLLMs将节省大量时间和资源,因为其成本更低、速度更快,且结果更具一致性。GLLMS在回忆和记忆大量信息方面也远超人类水平。
劣势:积极性高的人工研究助理通常只需极少的指示就能提供高质量的成果,而GLLMS可能需要设计提示工程或微调,才能生成同等质量的输出。因此人工编码对于样本量较小的复杂任务而言更适用。生成式大语言模型可能需要通过明确的示例来学习领域知识,但这些示例可能很难获取或构思。
四步使用框架构建:
步骤1定义并理解问题:评估所需的信息,包括特定领域的知识、上下文信息、必需的其他相关细节,避免模型因信息不足产生“幻觉”;
步骤2选择方法与模型:结合任务复杂度、成本、数据共享限制,选择零样本、少样本、微调三种向GLLMs下达指令的方法;
步骤3提示工程:设计清晰指令与机器可读的输出格式(如JSON),优化token使用以降低成本;
步骤4结构效度评估:通过人工标注的评估集验证模型性能,避免过度信任表面合理的输出。
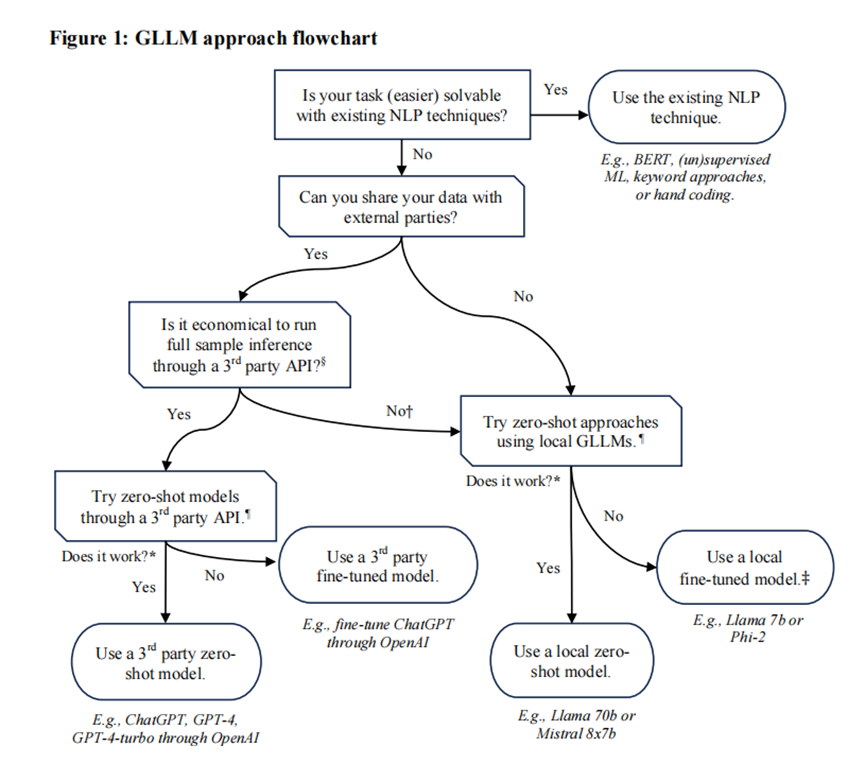
图1 GLLM方法流程图
三、案例验证
将GLLMs应用于识别财报电话会议中的非实质性回答这一棘手的自然语言处理问题,并与传统的机器学习方法做对比。
来源:通过Finnhub.io API获取2013-2022年(涵盖COVID-19时期)的业绩电话会议transcripts,匹配Gow等人(2021)样本中的CIK代码;
规模:最终得到63,959个业绩电话会议,提取1,152,505个问答对(Q&A pairs),并人工标注500个问答对作为评估集,400个问答对用于非回答维度分类验证;
辅助数据:Gow等人(2021)公开的代码与数据(用于基准方法复现),GPT-4生成的训练数据(用于模型微调)。
四、研究结果
分类方式:
(1) Manual(人工标注):基准参照组,423个回答、77个非回答,为所有方法提供“真实标签”
(2) Gow et al. (2021):传统规则化方法(基于正则表达式),文章复现的基准方法
(3) ChatGPT Zero-shot :零样本ChatGPT(GPT-3.5-turbo),无训练数据,仅通过提示完成分类
(4) GPT-4 Zero-shot:零样本GPT-4,无训练数据,直接通过提示分类
(5) 混合策略1(关键词+GPT-3+ChatGPT):分阶段筛选:先关键词过滤→GPT-3 Babbage模型预筛选→零样本ChatGPT分类
(6) 混合策略2(策略5+ChatGPT微调):在策略5基础上,用GPT-4生成+人工修正的训练数据微调ChatGPT,提升性能。
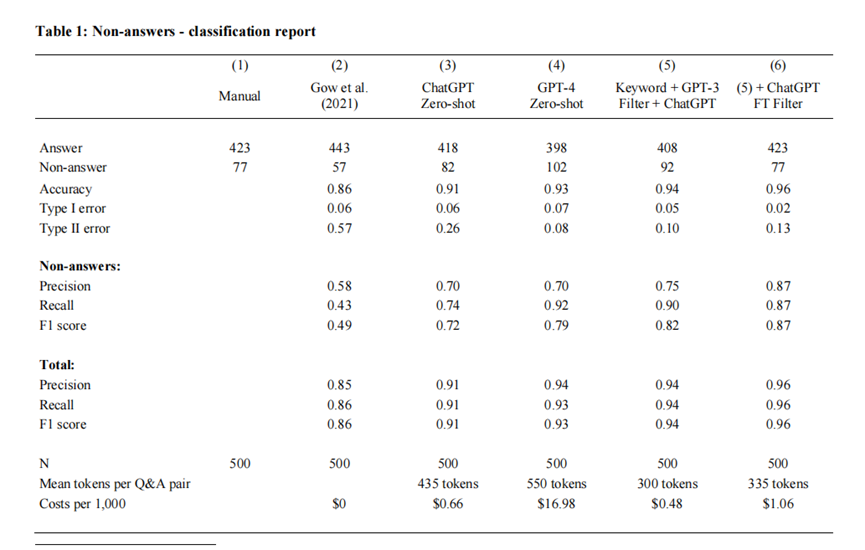
表1说明如果设置正确,GLLMs可以解决困难的NLP问题。第5列和第6列中的方法还强调,将GLLM与现有方法相结合有助于以合理的成本实现最先进的性能。
使用零样本的GPT-4创建初始训练数据集手动检查这些回答以纠正错误,然后在最终的数据集上对ChatGPT模型进行微调,以便同时从多个额外维度对非实质性回答进行分类:不提供答案的理由、非实质性回答的类型、非实质性回答之前问题的类型,以及管理者是否试图对非实质性回答赋予积极的情感倾向。
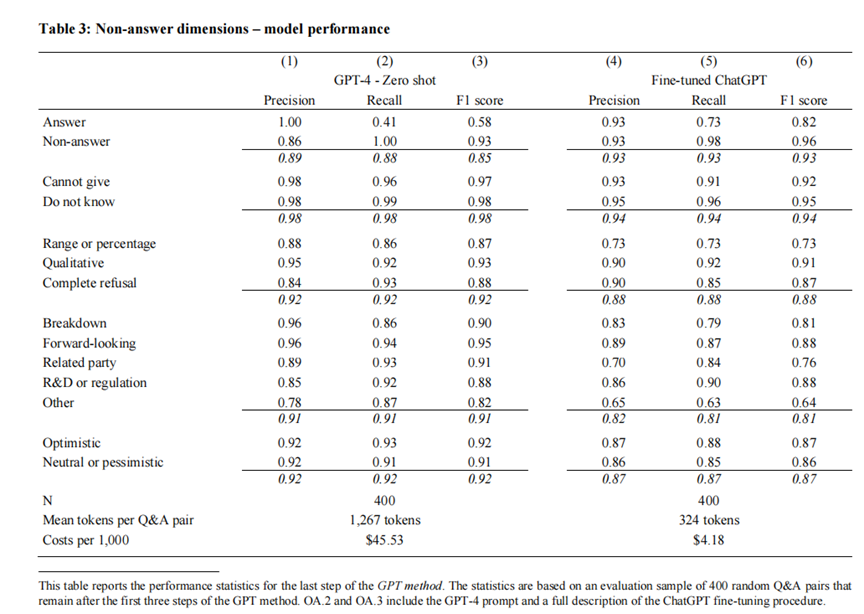
GPT-4方法(第(1)-(3)列)在所有类别中都表现出较高的性能,但成本高昂。微调后的ChatGPT方法(第(4)-(6)列)在非实质性回答分类上的性能更好,但在四个额外维度上的F1分数略低。
财报电话会议中,管理层对于不同类型问题的回应策略显示出一定的模式。
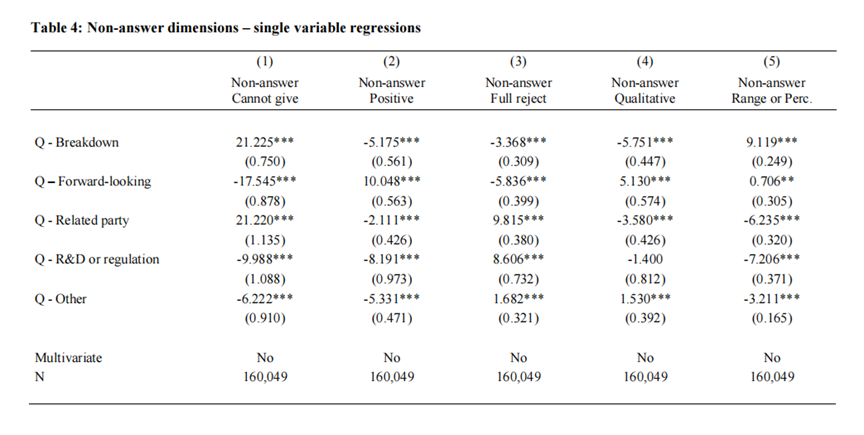
细分或关联方问题:由于政策或专有性考量,经理们通常不会透露信息。
前瞻性问题或研发监管问题:经理们倾向于表示不确定,可能是为了避免敏感信息影响市场。
积极回应:面对未来展望问题,经理们会强调公司的长期增长和战略优势。
直接拒绝回答:当问题涉及关联方或研发法规时,可能会因包含敏感或机密信息而被直接拒绝。
比较疫情前后未答案数量的变化,评估疫情对未回答问题的影响。
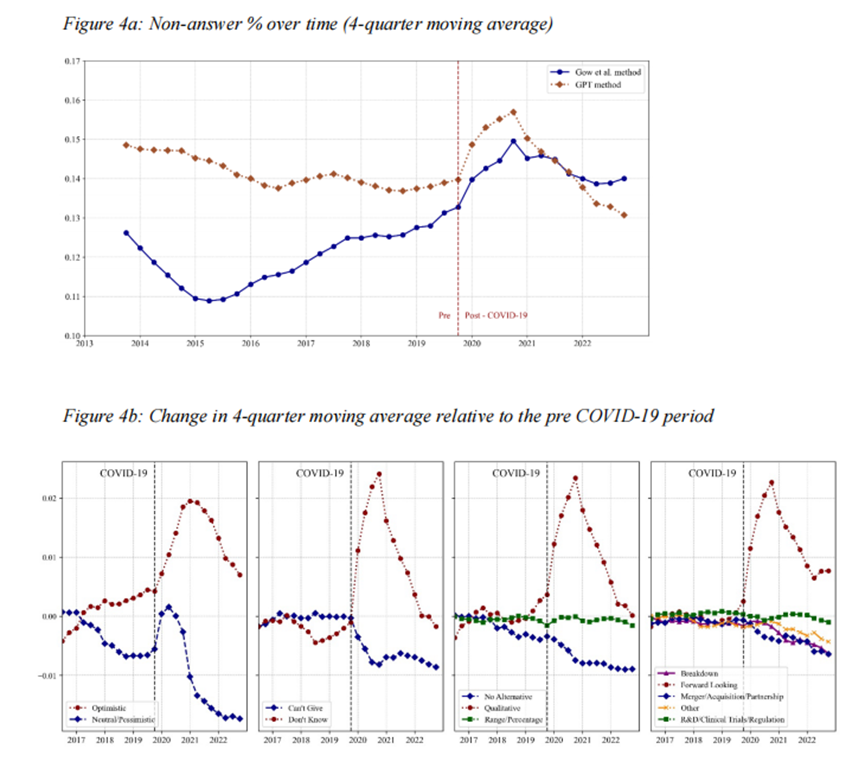
(a)中显示出在新冠疫情期间非实质性回答有所增加。(b)中的细分情况表明,上述情况是由于管理者对前瞻性问题提供定性非实质性回答并以不知道答案为由进行解释的情况增多所致。
五、讨论与结论
GLLMs的应用价值与边界:GLLMs在复杂、少样本文本任务中优势显著,但在大规模简单任务中不及非生成式模型,小样本专业任务中不及人工编码,需与传统方法协同使用。
关键挑战与应对:GLLMs的偏差、可复现性、数据共享风险需通过“提示补充专业信息”“存储原始提示”“优先本地模型”等策略应对,确保研究可靠。
混合策略的创新意义:“传统方法+GLLMs”的混合策略打破技术二元选择,为类似文本分析任务提供可复用范式,推动会计研究方法优化。
六、研究贡献
1)实践贡献
本研究介绍了如何在研究项目中有效运用GLLMS,并提供了相关框架本研究设计的新的GPT方法达到了96%的准确率,相较于其他方法,非实质性回答错误率降低了70%。
在线附录和配套网站提供了更多实用资源,比如不同模型的详细对比以及使用GLLMs入门的代码示例。
2)理论贡献
指出了GLLMS在可控性、结构效度、可重复性以及数据共享等方面存在的局限性与挑战。
资料来源:中智院微信公众号